Putting a Number on AI Consciousness
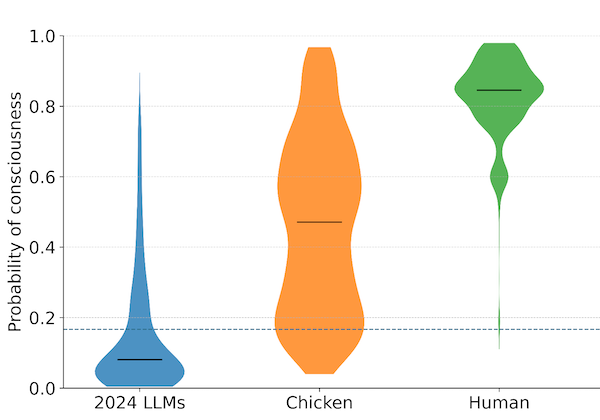
In January 2026, a team of researchers including Derek Shiller, Laura Duffy, Arvo Muñoz Morán, Adrià Moret, Chris Percy, and Hayley Clatterbuck published the initial results of the Digital Consciousness Model, a Bayesian framework for estimating the probability that AI systems are conscious. The paper is notable for what it attempts: a systematic, probabilistic assessment of AI consciousness that incorporates multiple theories rather than relying on any single one. It is also notable for its headline finding. Under the model’s aggregated analysis, the estimated posterior probability that 2024 large language models are conscious is 0.08, or about 8%. That figure is below the model’s prior of roughly 17%, meaning the evidence the model considers makes LLM consciousness less likely than the starting assumption. The same model places human consciousness at 0.85, chicken consciousness at 0.47, and ELIZA, the 1960s chatbot, at 0.006.
These numbers invite attention, and the authors are careful to discourage readers from taking them at face value. The absolute posterior probabilities, they note, are highly sensitive to the choice of prior. Change the prior and the posteriors shift substantially, though the comparative orderings generally hold. The paper’s authors explicitly state that they “do not straightforwardly endorse the median posterior probabilities” and that they think “it would be a mistake to conclude that LLMs have an 8% chance of being conscious.” What they do endorse are the comparative results: the direction in which the evidence pushes (against LLM consciousness, strongly for human consciousness), and the relative strength of that evidence across systems.
The architecture of the model deserves examination. It operates on three layers. The bottom layer consists of 206 indicators, observable or near-observable properties of a system. The middle layer consists of 20 features, general properties relevant to consciousness. The top layer consists of 13 “stances,” theoretical perspectives on what consciousness requires. The stances range from well-established neuroscientific theories like Global Workspace Theory and Recurrent Processing Theory to more speculative proposals like electromagnetic field mechanisms. For each system being assessed, expert reviewers estimate whether the system possesses the relevant indicators, and those estimates propagate upward through the model to update the probability of consciousness for that system under each stance. The stance-specific probabilities are then aggregated, either by equal weighting or by plausibility weights derived from expert ratings.
The result is a framework that makes its assumptions explicit and allows others to adjust any of them. A user who finds Global Workspace Theory more plausible than Attention Schema Theory can weight it accordingly and observe what happens to the output. If new evidence emerges about whether LLMs maintain internal self-models, that evidence can be fed into the indicators and the model updates. This modularity is one of the paper’s genuine strengths.
The results across stances reveal something important about the structure of the disagreement. LLMs score highest on what the paper calls the “Cognitive Complexity” and “Person-like” stances, perspectives that focus on behavioral sophistication and human-like social interaction. They score lowest on “Embodied Agency” and “Biological Analogy” stances, which emphasize physical embodiment or biological substrates. Chickens show the reverse pattern. This divergence illustrates why the field cannot converge on an answer: the question of whether a system is conscious depends heavily on which theory of consciousness one finds most credible, and the theories disagree about what matters.
To understand the significance of this work, it helps to situate it within the broader literature. In 2023, a large team including Patrick Butlin, Robert Long, Jonathan Birch, and David Chalmers published “Consciousness in Artificial Intelligence: Insights from the Science of Consciousness”, which derived indicator properties from neuroscientific theories and used them to assess existing AI systems. That paper concluded that no current AI systems are conscious but that there are “no obvious technical barriers” to building ones that satisfy the indicators. It was a landmark contribution. It operated primarily by asking whether systems possessed specific indicators, without formally quantifying the overall probability of consciousness.
The DCM builds directly on this foundation. Where Butlin et al. provided the conceptual vocabulary, identifying which properties might be relevant indicators of consciousness, the DCM adds a statistical layer: a Bayesian structure that formally relates indicators to features to theoretical stances, with explicit priors and conditional probabilities. It moves from a qualitative checklist to a quantitative model.
A different kind of argument comes from Simon Goldstein and Cameron Domenico Kirk-Giannini, who in 2024 published “A Case for AI Consciousness”, arguing that if Global Workspace Theory is correct, then existing language agents might already be phenomenally conscious or could easily be made so. This is a single-theory argument, and its strength depends entirely on whether GWT is the right theory. The DCM incorporates GWT as one of its thirteen stances, but its innovation is to avoid betting on any single theory. Under GWT alone, the DCM’s results for LLMs would look different than they do under the aggregated model.
Robert Long, Jeff Sebo, and collaborators including Butlin and Chalmers published “Taking AI Welfare Seriously” in late 2024, arguing that the realistic possibility of AI consciousness in the near future creates a responsibility for AI companies to begin assessing their systems and preparing policies. That paper focused less on the probability question and more on what should be done given the uncertainty. The DCM offers something these authors called for: a systematic assessment tool. Whether the DCM is that tool in its current form is debatable, but it takes a concrete step toward what Long, Sebo, and their coauthors described as a need.
Eric Schwitzgebel has been writing about these questions for over a decade. His 2025 paper “AI and Consciousness” addresses the broader philosophical landscape, including the risk of what he has called the “moral gray zone” where we genuinely cannot tell whether a system deserves moral consideration. His earlier work with Mara Garza defending the potential rights of artificial intelligences (2015) and Jeff Sebo and Robert Long’s argument for moral consideration of AI systems by 2030 both underscore that the question the DCM addresses has practical stakes. If there is a nonzero probability that AI systems are conscious, and that probability is not negligible, consequences follow.
The DCM’s 8% figure, even with the authors’ caveats about its sensitivity to priors, lands in precisely the territory these scholars have been warning about. It is low enough that dismissal feels tempting, and high enough that dismissal feels irresponsible. A system that has an 8% chance of being conscious under one set of assumptions, and a different probability under different assumptions that reasonable people hold, is a system where the question cannot be closed.
Several aspects of the DCM deserve scrutiny. The model relies on expert estimates for indicator values, and the authors acknowledge that these estimates involve judgment calls about vague properties. When an expert is asked whether a system “systematically prefers certain types of activities,” the answer depends on what the expert thinks it means to genuinely have preferences, which is itself a contested question. The indicators are meant to be near-observable, but many of them encode theoretical commitments that are doing unacknowledged work.
The choice of 13 stances also shapes the results. Stances are not all equally developed or equally supported by evidence. The paper acknowledges this and offers plausibility-weighted aggregation as a partial remedy, but the weights themselves come from a small pilot study (n=13 experts) with significant heterogeneity. Adding or removing a stance, or changing the weights, could shift the aggregated results. The model is transparent about these dependencies, which is to its credit. Transparency about fragility is still fragility.
The most significant question the DCM raises may be one it cannot answer: what should we do with a probability estimate for consciousness? The philosophical literature has not converged on how probability and moral consideration interact. A 50% chance of consciousness does not obviously entail 50% of the moral consideration owed to a definitely conscious being. Jonathan Birch has argued for a precautionary approach: that even a relatively low probability of sentience should trigger certain protections. Others have argued that probability estimates for consciousness are not meaningful in the way that probability estimates for physical events are, because we lack an agreed-upon measure. The DCM provides a number. The framework for interpreting that number ethically and practically does not yet exist.
For people working on institutional readiness, the DCM matters because it demonstrates that the question of AI consciousness can be submitted to formal analysis. It makes the structure of the disagreement visible in a way that verbal arguments do not: the stances, indicators, and features are all laid out, and anyone can see which assumptions drive which conclusions. Most importantly, it produces a result that sits in the uncomfortable middle ground between certainty and dismissal. That middle ground is where most serious researchers now locate themselves. It is also where the practical questions live. The institutions, policies, and professional frameworks that will need to handle AI consciousness questions are being asked to operate in a space where the probability is neither zero nor one, and the DCM makes that space concrete.
Shiller, D., Duffy, L., Muñoz Morán, A., Moret, A., Percy, C., & Clatterbuck, H. (2026). “Initial results of the Digital Consciousness Model.” arXiv:2601.17060.










